결정계수 (Coefficient of Determination)는 회귀 분석에서 모델이 주어진 데이터에 얼마나 잘 적합되는지를 나타내는 지표입니다. 주로 R^2로 표기되며, 0과 1 사이의 값을 가지며 높을수록 모델이 데이터를 잘 설명하고 있다는 것을 의미합니다. 결정계수는 주어진 데이터의 분산 중에서 회귀 모델에 의해 설명되는 분산의 비율을 나타냅니다.
SSR (Sum of Squares Regression)
SSR은 회귀 모델이 독립 변수(입력 변수)로 종속 변수(출력 변수)를 얼마나 잘 설명하는지를 나타내는 값입니다. 즉, 회귀 모델이 예측한 값과 평균값의 차이를 제곱하여 모두 더한 값으로, 회귀 모델이 설명하는 종속 변수의 분산을 측정합니다. SSR은 모델이 데이터에 대해 설명할 수 있는 변동의 정도를 나타냅니다.
SST (Sum of Squares Total)
SST는 종속 변수의 전체 변동을 나타냅니다. 데이터 전체의 분산을 측정하는 값으로, 종속 변수 값들과 평균값 간의 차이를 제곱하여 모두 더한 값입니다. SST는 종속 변수의 변동을 전체적으로 평가하는 지표로, 회귀 모델 없이 종속 변수의 분산을 설명합니다.
SSE (Sum of Squares Error)
SSE는 회귀 모델의 예측값과 실제 관측값 간의 차이를 제곱하여 모두 더한 값으로, 모델의 예측 오차의 크기를 측정합니다. 즉, 회귀 모델로 설명하지 못하는 종속 변수의 변동을 나타냅니다. SSE는 모델의 잔차(residual)를 평가하며, 모델이 데이터를 얼마나 잘 적합시키는지에 대한 정보를 담고 있습니다.
잔차(residual)는 회귀 분석에서 실제 관측값과 모델로 예측한 값 간의 차이를 의미합니다. 즉, 잔차는 모델이 예측하지 못한 나머지 부분으로, 데이터 포인트와 모델 예측값 간의 오차입니다. 잔차는 회귀 분석에서 모델의 적합도를 평가하고 모델의 예측력을 확인하는 데 사용됩니다.
잔차를 수식으로 나타내면 다음과 같습니다:
잔차 = 실제 관측값 − 모델로 예측한 값
각 데이터 포인트마다 잔차를 계산하여 모든 잔차 값을 고려하면 모델의 예측이 실제 데이터와 얼마나 일치하는지, 어느 정도의 오차가 있는지 등을 파악할 수 있습니다. 회귀 분석에서 목표는 잔차를 최소화하는 모델을 찾는 것이며, 이를 통해 데이터에 대한 모델의 설명력과 예측 능력을 향상시킬 수 있습니다.
SSE (Sum of Squares Error)는 모든 데이터 포인트의 잔차를 제곱하여 합한 값으로, 모델이 데이터를 얼마나 잘 적합시키지 못하는지를 나타내는 지표입니다. SSE는 회귀 분석에서 모델의 적합도를 평가할 때 사용되며, 이 값이 작을수록 모델이 데이터를 더 잘 설명한다고 볼 수 있습니다.
회귀분석에서의 "잔차(residual)"와 딥 러닝 아키텍처에서의 "잔차"는 서로 다른 의미를 가지는 용어입니다.
회귀분석에서의 "잔차"는 관측된 종속 변수 값과 회귀 모델로 예측한 종속 변수 값 간의 차이를 의미합니다. 간단히 말하면, 회귀 모델이 실제 데이터에 얼마나 잘 적합되었는지를 나타내는 값입니다. 잔차는 다음과 같이 계산됩니다:
잔차 = 실제 관측 값−모델 예측 값
딥 러닝 아키텍처에서의 "잔차(residual)"는 제가 이전에 설명한 것처럼, 네트워크의 입력과 출력 간의 차이나 남은 부분을 나타냅니다. 이것은 주로 그레이디언트 소실 문제를 해결하고 학습 안정성을 향상시키기 위해 사용되는 개념입니다.
요약하면, 회귀분석에서의 "잔차"는 모델의 예측 값과 실제 관측 값 간의 차이를 나타내는 반면, 딥 러닝 아키텍처에
서의 "잔차"는 네트워크의 입력과 출력 간의 차이를 나타내는 개념입니다.
결정계수 R^2는 다음과 같이 계산됩니다.
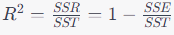
결정계수 해석
결정계수(R^2) 값의 해석은 모델이 주어진 데이터를 얼마나 잘 설명하는지를 평가하는 데 중요합니다. R^2 값은 0에서 1 사이의 범위를 가지며, 그 값에 따라 모델의 설명력이나 예측 능력을 판단할 수 있습니다.
R^2 = 0: 모델이 주어진 데이터를 전혀 설명하지 못하는 경우입니다. 종속 변수의 변동을 모델로 설명할 수 없음을 의미합니다.
R^2 = 1: 모델이 주어진 데이터를 완벽하게 설명하는 경우입니다. 모든 종속 변수의 변동을 모델이 설명하고 있음을 의미합니다. 다만, 실제로는 대부분의 상황에서 완벽한 설명은 어렵기 때문에 R^2 값이 1에 가까워지는 경우는 드뭅니다.
0 < R^2 < 1: 대부분의 경우에서 R^2 값은 이 범위에 속합니다. 이 범위의 값은 데이터에 대한 모델의 설명력을 나타냅니다. 높은 R^2 값은 모델이 데이터를 잘 설명하고 있다는 것을 의미하며, 낮은 R^2 값은 모델이 데이터를 설명하지 못하거나 다른 변수가 추가되어야 할 수 있음을 나타냅니다.
R^2 = 0.5: 일반적으로 R^2 값이 0.5 이상인 경우, 모델이 데이터를 상당 부분 설명하고 있다고 판단할 수 있습니다. 하지만 이 값은 상황에 따라 달라질 수 있습니다. 분야에 따라서는 높은 R^2 값이 필요한 경우와 그렇지 않은 경우가 있을 수 있습니다.
R^2의 함정: R^2는 설명력을 나타내는 유용한 지표이지만, 주의해야 할 점도 있습니다. 예를 들어, 독립 변수 중 하나만을 추가해도 R^2 값이 증가할 수 있습니다. 따라서 모델을 평가할 때에는 다른 평가 지표와 함께 고려하는 것이 중요합니다. 또한, 과적합(Overfitting) 상황에서 R^2 값이 높게 나올 수 있으므로 이러한 상황을 판단하기 위해서는 다른 검증 기법들을 사용해야 합니다.
종합적으로, R^2 값은 모델의 성능을 평가하는 중요한 지표 중 하나이지만, 다양한 요소들과 함께 고려하여 모델의 신뢰성을 평가하는 것이 좋습니다.
R2 스코어 계산
r2_socre
R2 스코어를 계산하는 함수는 Python에서 scikit-learn 라이브러리를 사용하면 간단하게 구현할 수 있습니다. 아래는 scikit-learn을 사용하여 R2 스코어를 계산하는 예제 코드입니다:
from sklearn.metrics import r2_score
# 실제 관측 값
actual_values = [2.5, 3.7, 4.2, 5.0, 6.1]
# 모델의 예측 값
predicted_values = [2.7, 3.5, 4.0, 5.2, 6.0]
# R2 스코어 계산
r2 = r2_score(actual_values, predicted_values)
print("R2 스코어:", r2)
실제 관측 값과 모델의 예측 값에 해당하는 데이터를 준비하고, r2_score() 함수에 실제 값과 예측 값 리스트를 전달하여 R2 스코어를 계산할 수 있습니다.
만약 직접 R2 스코어를 계산하고자 한다면, 다음과 같은 수식으로 계산할 수 있습니다:
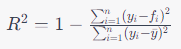

입니다. 하지만 보통은 라이브러리 함수를 사용하여 편리하게 계산합니다.
model.score
머신 러닝 모델에서 주로 사용하는 score() 함수는 각 모델마다 다를 수 있습니다. 그러나 대부분의 경우, 회귀 모델의 score() 함수는 R2 스코어 값을 반환합니다. scikit-learn의 score() 함수를 사용하면 R2 스코어를 쉽게 계산할 수 있습니다.
아래는 scikit-learn을 사용하여 score() 함수를 이용해 R2 스코어를 계산하는 예제 코드입니다.
from sklearn.linear_model import LinearRegression
# 데이터 준비
X = [[1], [2], [3], [4], [5]]
y = [2.5, 3.7, 4.2, 5.0, 6.1]
# 모델 초기화
model = LinearRegression()
# 모델 훈련
model.fit(X, y)
# R2 스코어 계산 및 출력
r2 = model.score(X, y)
print("R2 스코어:", r2)
위 코드에서 LinearRegression 클래스를 사용하여 선형 회귀 모델을 초기화하고, 훈련합니다. 그리고 나서 score() 함수를 호출하여 R2 스코어 값을 얻을 수 있습니다.
주의할 점은, score() 함수의 인자로 사용되는 X와 y는 훈련에 사용한 데이터셋이어야 합니다. 이 함수는 훈련 데이터에 대한 모델의 성능을 측정하기 위해 사용됩니다. 만약 다른 데이터셋에 대한 R2 스코어를 계산하려면 해당 데이터셋을 사용하여 score() 함수를 호출하면 됩니다.
해당 게시글은 ChatGPT의 도움을 받아 작성되었습니다.
'AI > Machine-Learning' 카테고리의 다른 글
| RobustScaler (0) | 2023.08.29 |
|---|---|
| 다중 선형 회귀와 절차 (0) | 2023.08.29 |
| [Scikit-learn] LinearRegression, SGDRegressor (0) | 2023.08.28 |
| [NumPy] matmul(), dot() (0) | 2023.08.28 |
| Numpy rand(), randn() (0) | 2023.08.28 |



