피어슨 상관계수(Pearson Correlation Coefficient)
피어슨 상관계수는 두 변수 간의 선형 관계를 측정합니다. 주로 연속형 변수 간의 상관 관계를 계산하는 데 사용됩니다. 공식은 다음과 같습니다:
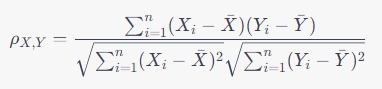

값의 범위: -1에서 1 사이의 값을 가지며, 다음과 같이 해석됩니다.
- 1에 가까우면, 강한 양의 선형 상관관계가 있음을 나타냅니다.
- -1에 가까우면, 강한 음의 선형 상관관계가 있음을 나타냅니다.
- 0에 가까우면, 선형 상관관계가 거의 없거나 매우 약할 가능성이 있습니다.
가정: 피어슨 상관계수를 사용하기 위해서는 두 변수가 정규분포를 따르고 선형성을 보이는 것이 중요합니다. 이러한 가정이 충족되지 않을 경우 해석이 왜곡될 수 있습니다.
스피어만 상관계수(Spearman Correlation Coefficient)
스피어만 상관계수는 두 변수 간의 단조 관계(모든 관측치 쌍에서 하나의 변수가 증가하면 다른 변수도 증가하거나 감소하는 경우)를 측정합니다. 주로 순위 형식의 데이터나 비선형 관계를 가지는 변수 간의 상관 관계를 계산하는 데 사용됩니다. 공식은 다음과 같습니다:


값의 범위: -1에서 1 사이의 값을 가지며, 피어슨 상관계수와 유사하게 해석됩니다.
- 1에 가까우면, 강한 양의 순위 상관관계가 있음을 나타냅니다.
- -1에 가까우면, 강한 음의 순위 상관관계가 있음을 나타냅니다.
- 0에 가까우면, 순위 상관관계가 거의 없거나 매우 약할 가능성이 있습니다.
가정: 스피어만 상관계수는 데이터의 분포에 대한 가정이 필요하지 않으며, 비선형적인 관계도 감지할 수 있습니다. 따라서 정규분포나 선형성 가정이 필요 없습니다.
주요 차이점은 피어슨 상관계수는 선형 상관 관계를 측정하는 데 사용되며, 스피어만 상관계수는 순위 또는 단조 상관 관계를 측정하는 데 사용된다는 점입니다. 어떤 상관계수를 사용할지는 데이터의 성격과 연구 목적에 따라 다릅니다.
예제
Pandas를 사용한 상관계수 계산
Pandas의 DataFrame을 사용하여 상관계수를 계산할 수 있습니다.
import pandas as pd
# 예제 데이터 생성
data = {'X': [3, 2, 1, 4, 5], 'Y': [4, 2, 3, 1, 5]}
df = pd.DataFrame(data)
# 피어슨 상관계수 계산
pearson_corr = df['X'].corr(df['Y'], method='pearson')
print("피어슨 상관계수:", pearson_corr)
# 스피어만 상관계수 계산
spearman_corr = df['X'].corr(df['Y'], method='spearman')
print("스피어만 상관계수:", spearman_corr)
위 코드에서 corr 함수를 사용하여 피어슨 상관계수와 스피어만 상관계수를 계산합니다. method 매개변수를 사용하여 계산 방법을 선택할 수 있습니다.
scipy.stats를 사용한 상관계수 계산
import numpy as np
import scipy.stats
# 예제 데이터 생성
# X와 Y는 순서가 있는 범주형 데이터 또는 서열 데이터로 가정합니다.
X = [3, 2, 1, 4, 5]
Y = [4, 2, 3, 1, 5]
# 피어슨 상관계수 계산
pearson_corr, _ = scipy.stats.pearsonr(X, Y)
print("피어슨 상관계수:", pearson_corr)
# 스피어만 상관계수 계산
spearman_corr, _ = scipy.stats.spearmanr(X, Y)
print("스피어만 상관계수:", spearman_corr)이 코드는 예제 데이터로 순서가 있는 범주형 데이터를 사용하여 피어슨 상관계수와 스피어만 상관계수를 계산하는 방법을 보여줍니다. scipy.stats 모듈을 사용하여 계산합니다.
먼저, pearsonr 함수를 사용하여 피어슨 상관계수를 계산하고, 그 값을 출력합니다. 그 다음, spearmanr 함수를 사용하여 스피어만 상관계수를 계산하고, 그 값을 출력합니다.
데이터를 적절히 대체하여 원하는 데이터로 실험할 수 있습니다. 위 코드는 순서가 있는 범주형 데이터를 사용한 예제이지만, 순서형 데이터 또는 서열 데이터에도 적용할 수 있습니다.
해당 게시글은 ChatGPT의 도움을 받아 작성되었습니다.
'Big Data > DataAnalysis & Manipulate' 카테고리의 다른 글
| [Pandas] 데이터프레임의 요소 간 비교 및 조작 (0) | 2023.11.06 |
|---|---|
| [Pandas] datetime 프로퍼티 (0) | 2023.09.08 |
| [pandas] columns.difference (0) | 2023.08.28 |
| 데이터 스케일러(StandardScaler, MinMaxScaler) (0) | 2023.08.25 |
| Apriori 알고리즘 (0) | 2023.08.16 |



